什么是爬虫?用大白话讲清楚网络爬虫到底是干嘛的

目录
💡 一句话概述
爬虫不是黑科技,也不是黑客工具,它就是一个用程序模拟人操作网站的自动化工具,专门用来替人干那些枯燥、重复、耗时间的网页操作和数据整理工作。

🧠 什么是爬虫?
在中文领域,它的专业术语叫“网络爬虫”。但说实话,这个名字一出来,很多人已经开始头大了。你要是去看百度词条,普通人看一天也看不懂,因为内容又老旧又学术。爬虫本质上是个工程化的东西,靠一句“自动抓取信息的程序”根本解释不清。
所以我们不走学术路线,走工程路线,说人话就行:
爬虫 = 模拟
模拟人是怎么用网站的,只不过这个“人”换成了程序。
🔍 爬虫的两种模拟方式
爬虫主要就两种模拟方式。
① 你看不到的模拟
第一种是你看不到的模拟,它本质是在模拟“数据包”。你刷手机的时候能打电话、能上网、能发微信,你看到的是界面,但真正干活的是你看不见的手机信号。第一种爬虫就像这个信号,你看不见,它一直在跑,直接跟服务器说话,不绕弯子。
一句话概括:
它是“隔空取物型爬虫”,就像打电话给仓库说:
“喂,把数据给我打包发过来。”
特点是:快、狠、省资源、效率高。

② 你能看到的模拟
第二种是你能看到的模拟。这个就非常“老实”,它真的给你开一个浏览器:打开网页、点按钮、滚页面、输入账号密码,只不过手不是你的,是程序在点。
你可以理解成给电脑装了一只“电子手”,帮你刷网页、干体力活。
一句话概括:
这种爬虫是“真人替身型爬虫”,就像请了一个不会累、不会抱怨的实习生。

🛠️ 爬虫工程的两条路
基于这两种模拟方式,爬虫在工程上其实就两条路:
一种是模拟数据包(requests等),像是给仓库打电话、直接进货、服务器大哥直接开车送过来。
优点是:快、稳、成本低;
缺点是:你得知道“仓库门在哪”,也就是你得先找到数据接口。
另一种是直接模拟浏览器(selenium等),像是自己进商场、推着购物车、一件一件拿。
优点是:只要人能看到的,它基本都能拿;
缺点是:慢一点、资源消耗大一点。
其实在实战中还有系统级模仿以及混合方式,由于是科普文章,这里就不多讲了。
一句话总结:
requests 直接打电话进货,
selenium 推着小车去商场买。
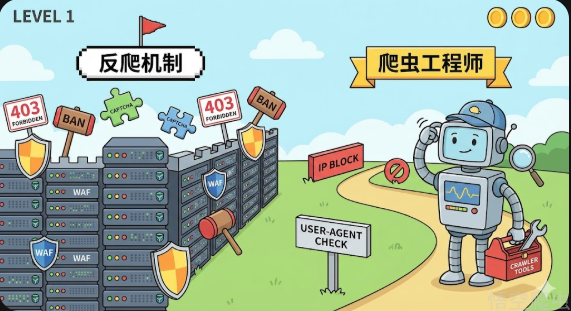
⚔️ 攻防大战:为什么爬虫没那么简单?
很多人以为爬虫要么很难,要么很简单,其实这两种想法都不对。爬虫本质是一种“攻防”,必须结合具体业务来看:有的场景很简单,有的场景非常难。
大型网站也不傻,你要搬它的数据,它一定会怀疑:
“你是不是机器人?”
于是就有了各种反爬机制:
- 验证码:证明你不是机器人
- 封 IP:这条街不欢迎你
- 账号限制:不登录不给你看
这时候爬虫工程师就像在打游戏升级装备:
- 代理 IP 池:一个号被封就换个马甲
- 验证码识别:你出题我自动做
- 模拟人类行为:点慢一点、停一停、像真人一样操作
这已经不是写几行代码的事了,而是标准的工程对抗。
🚀 爬虫能用来干嘛?
别以为它只是“偷数据”,它其实是很多高科技应用的地基:
- 比价工具:自动监测全网电商价格变化
- 舆情监控:实时分析网上的舆论走向
- AI 训练:大模型吃数据,爬虫是“铲屎官”
没有爬虫,AI 连饭都没得吃。
⚖️ 爬虫的职业操守与边界
很多人会说:“那是不是只要遵守 Robots 协议就行了?”
这话对,也不完全对。Robots 协议本质上是个“君子协议”,并没有强制法律效力。如果它真能解决问题,也就不需要这么多爬虫攻防了。但部分司法案例会将其作为“合理访问边界”的参考依据。
真正的红线在这里:
- 把服务器爬宕机 → 民事责任
- 爬取公民隐私数据 → 刑事责任
- 数据用途构成不当竞争 → 法律风险
所以江湖有句玩笑话:
“爬虫写得好,牢饭吃到饱。”
是玩笑,但提醒是认真的。
🧱 最后的总结
说白了,爬虫就是个“高级打工仔”。
人刷网页会累、会烦、会手酸,它不会。
人一天能点几百次,它一天能点几百万次。
人容易漏数据、抄错数据,它一条不漏,一条不错。
爬虫存在的意义只有一个:
不是炫技术,
不是搞神秘,
而是把那些枯燥、重复、没人愿意一直干的活,
全部交给电脑去干。
人负责思考,
机器负责搬砖。
这才是爬虫最真实、也最有价值的地方。