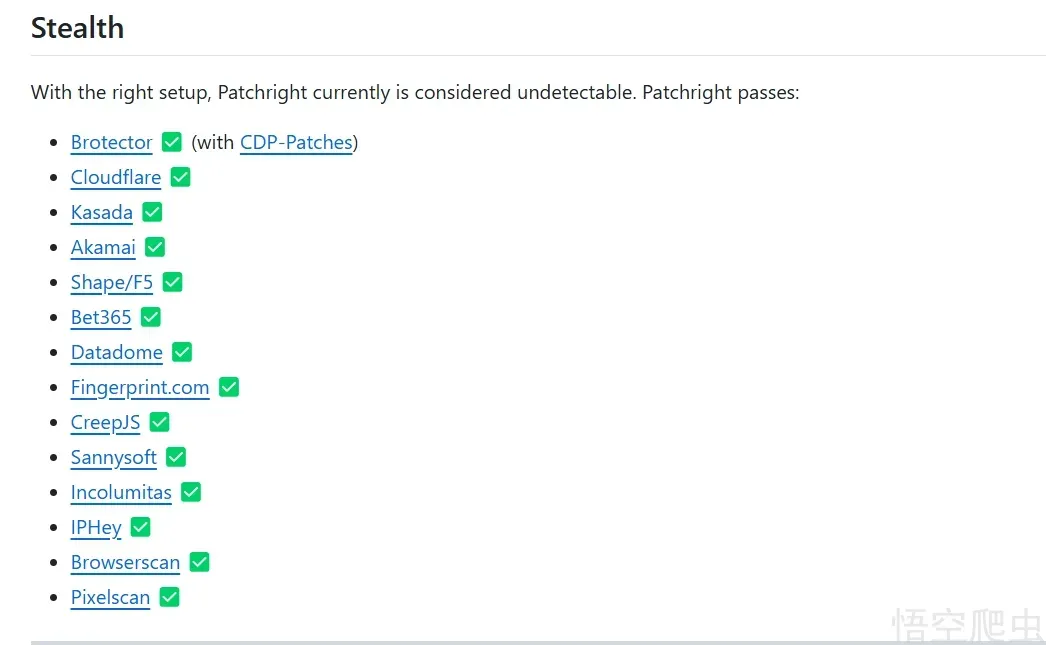
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| from DrissionPage import ChromiumPage, ChromiumOptions
import time
def access_protected_site(url):
# 配置浏览器选项
co = ChromiumOptions()
co.set_argument('--no-sandbox')
co.set_argument('--disable-gpu')
# 初始化浏览器
page = ChromiumPage(co)
try:
print(f"正在访问: {url}")
page.get(url)
if page.wait.ele_displayed('text:Checking your browser', timeout=2):
print("检测到 Cloudflare 验证层,等待自动处理...")
# 也可以手动尝试点击复选框(如果自动失败的话)
# page.ele('@id:cf-turnstile-wrapper', timeout=5).click()
# 等待正文内容出现,例如文章标题
# 根据 shift-journal.org 的结构,通常文章会有特定的 class 或 tag
if page.wait.ele_displayed('tag:h1', timeout=15):
print("成功绕过验证,正在提取数据...")
# 获取页面标题和部分内容
title = page.ele('tag:h1').text
content = page.html # 或者使用 page.ele('article').text
print("-" * 30)
print(f"文章标题: {title}")
print(f"页面源码长度: {len(content)}")
print("-" * 30)
else:
print("未能成功加载页面内容,可能被彻底封锁或需要手动处理验证码。")
except Exception as e:
print(f"发生错误: {e}")
finally:
time.sleep(5)
# page.quit()
if __name__ == "__main__":
target_url = "https://www.shift-journal.org/article/742beb12-f075-4279-9a05-9577f23c9734"
access_protected_site(target_url)
|