24小时被AI爬36次,扎克伯格缺数据缺疯了

24小时被AI爬36次,扎克伯格缺数据缺疯了
大家好,我是彪哥。
我的博客上线大概半年,平时写点技术干货。
本以为读者都是咱们国内搞技术的哥们儿,结果打开 Cloudflare 的后台统计一看,
好家伙,我这儿快成“国际 AI 聚会中心”了。
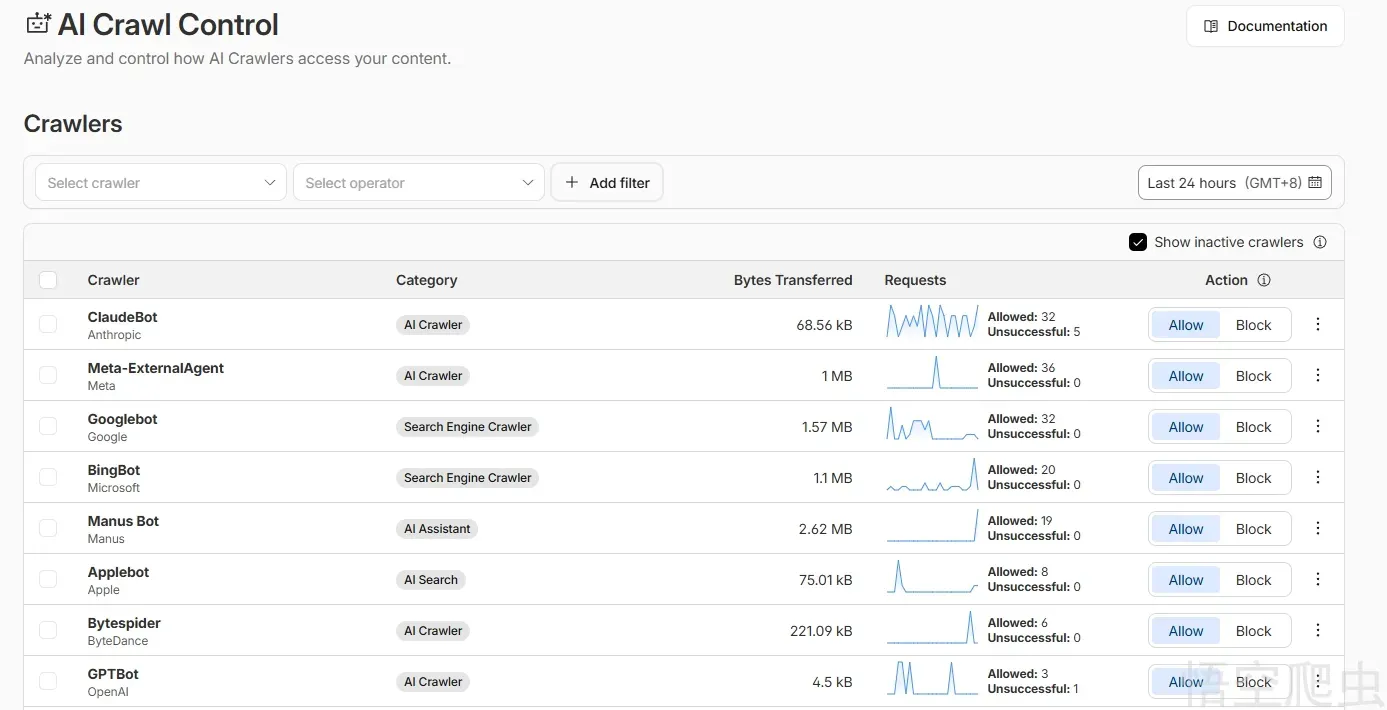
我把 Cloudflare 后台的 AI 爬虫数据拉了一下,统计了最近 24 小时:
榜一大哥:Meta-ExternalAgent (Meta/扎克伯格)
请求数36次。流量跑了 1MB。
小扎现在的 Llama 模型缺中文语料缺疯了,全网掘地三尺,连我这种小博客都不放过。
榜二大哥:ClaudeBot (Anthropic)
请求数31次。虽然失败了 5 次,但依然锲而不舍。
Claude 现在的中文逻辑好,很大程度上就是因为这类爬虫抓得勤。
榜三大哥:Googlebot (谷歌)
请求数32次。老牌大哥,依然很稳。
榜四:BingBot (微软/Bing)
请求数20次。
大家发现没有?AI 爬虫的活跃度已经完全跟传统搜索引擎(谷歌、Bing)并驾齐驱,甚至开始反超了。
我们把“请求次数”和“流量”结合起来看,会发现一件更有意思的事情:
这些AI爬虫,不只是来“看”,而是在用不同方式“吃”内容。
简单来说,可以分成两类:
第一类:高频扫荡型(看得多,但不深)
比如Meta和Claude,
这类爬虫的特点是:请求次数很高,但单次流量不算特别大。

第二类:深度搬运型
像是Google,Bing。
请求次数不一定最多,但流量非常高。
说明不是简单记录链接,而是在“完整采集内容”。
这些爬虫有的负责“发现内容”,有的负责“深度消化”,
最终的目标只有一个,
把整个互联网,重新整理进它们的AI模型里。
可能有人会问:一个小博客,有什么好爬的?
其实程序员博客有一个共同点,结构清晰 + 能直接解决问题,
而这,正是 AI 最喜欢的东西。
因为 AI 的工作,本质上就是:把“问题”变成“答案”。
互联网上的每一篇教程,对它来说,都是现成的训练素材。
我得跟大家强调一点,我这博客只是个“小透明”啊!
我这儿满打满算没多少文章,一天就被这帮巨头轮番“蹂躏”几十次。
那些日活千万的垂直社区(知乎、豆瓣、小红书)每天面临的是什么?
那些技术大牛的独立站点每天要承受什么样的抓取压力?
这种“数字化采矿”已经到了丧心病狂的地步,
现在的互联网,其实正在变的中心化——所有的知识都在往几家 AI 巨头那里汇集。
在我的这份活跃AI爬虫名单里,除了字节跳动的 Bytespider (6次) 象征性地露了个面,剩下的全是海外巨头。
国内那些的其它大厂爬虫去哪了?
这事儿挺有意思的。

作为一个博客作者,我有一个感受,现在写博客,第一读者,已经不是人了。
过去十年,我们写文章,是为了让人通过搜索找到我们。
但现在的路径,变成,
写文章 → AI 先读 → 再决定有没有人看到你
说白了,现在写博客,已经有点变味了。
以前是写给人看的,现在是先写给 AI 看。
人能不能看到,反而变成第二步了。
你以为你在写文章, 其实已经在给 AI 打工了。
以前是人找答案,现在是 AI 先把答案吃了,再喂给人。
公众号和交流群
欢迎进群交流。
