我把 2000 多条 Seedance 2 提示词整理成了网站和开源数据集,随便你用

我把 2000 多条 Seedance 2 提示词整理成了网站和开源数据集,随便你用
自己做 AI 视频的时候,找 Seedance 2 的提示词太费劲了。
X、抖音、Discord 到处翻,找到的很多都是截图,没法复制。网上所谓的“提示词合集”,要么收费,要么只有干巴巴的文字,没有原视频、没有分类、没有结构,想深入研究根本用不了。
就想着自己整理一份吧。结果越整理越多,最后索性做成了一个网站 + 一个开源数据集。
网址是 prompthub.gokuscraper.com,打开就能用,不用注册,不用登录。
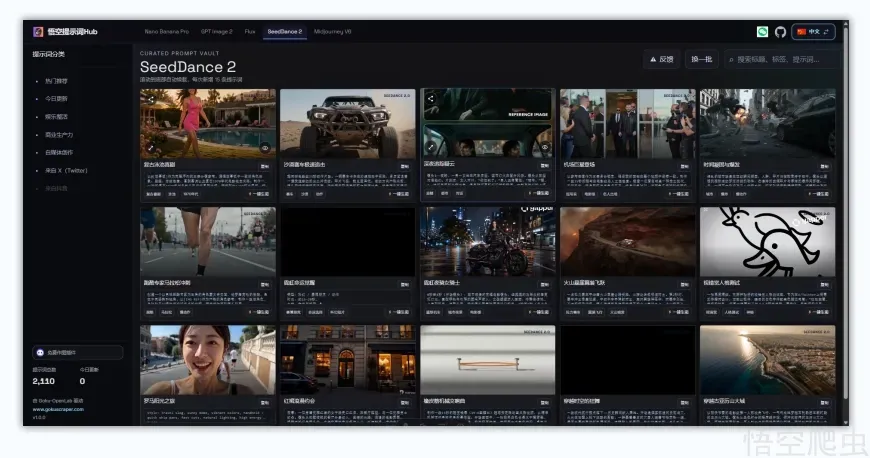
目前支持的模型有 Seedance 2、Midjourney V6、Flux、GPT Image 2、Nano Banana Pro 等,基本覆盖了主流的 AI 图像和视频生成工具。
提示词按用途分了几个类:热门推荐、今日更新、娱乐整活、商业生产力、自媒体创作,还有按来源分的“来自 X(Twitter)”和“来自抖音”,方便不同需求的人快速筛选。
每条提示词都有视频预览,不是纯文字列表,效果一目了然。支持按标题、标签、内容搜索,想找特定风格直接搜就行。点一下“复制”按钮,整段提示词直接拿走,不用手动划拉。
还有个“一键生图”⚡ 按钮,点了就能跳转去对应平台生成。翻到底部自动加载更多,像刷信息流一样,不知不觉就攒了一堆灵感。
但网站只是个壳,真正花心思的是背后的数据集。
如果只是搭个网站展示提示词,其实不用费这么大劲。但我从一开始就想着,这些数据不能只放在网页上看,得做成真正的开放数据。
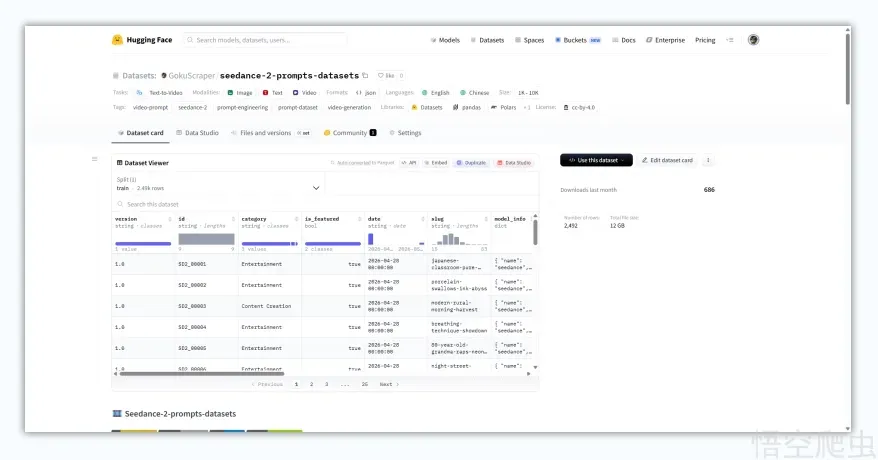
数据集叫 seedance-2-prompts-datasets,放在 Hugging Face 上,总量 12GB,包含 2110+ 条 Seedance 2.0 生成的视频(mp4)和封面图(jpg)。
核心是一个 metadata.jsonl 文件,每条提示词都做了结构化处理。标题、标签、中英文翻译、视频文件对应关系、分辨率、时长、安全评级,全部标好规整了。举个数据条目的例子:
json
| |
对于开发者来说,一行代码就能加载整个数据集:
python
| |
适合做研究、工具开发、模型训练等二次使用。整个数据集采用 CC BY 4.0 协议,商用也没问题,只需署名。
为什么非要费劲做成结构化数据?
AI 时代,提示词本质上是一种新的“生产力语言”。但现状是:好提示词散落在各个角落,截图、推文、视频评论区,零零碎碎,能找到但没法用。
我想做的事很简单:把散落的好提示词收集起来,做成机器能读、人能检索、开发者能直接用的数据。不只是“展示”,而是真正可计算、可二次开发的数据资产。
这个项目和网站只是第一步。
当然,现在远谈不上完善。
说实话,做完是一回事,做好是另一回事。这个项目和网站还有很多我自己都不太满意的地方,坦率列出来:
网站方面:
提示词总量 2110 条,对于一个想做成“Hub”的东西来说,远远不够
模型覆盖还不全,目前 Seedance 2 是主力,其他模型的量明显偏少
分类颗粒度可以更细,现在有些标签比较粗放
移动端体验没专门优化,手机上看还不够舒服
没有用户系统,收藏、点赞、个性化推荐这些都还没做
数据集方面:
结构化整理目前只覆盖了 Seedance 2,其他模型的高质量提示词还没纳入
数据来源偏重 X(Twitter)和抖音,其他平台内容少
更新目前主要靠人工,自动化采集和清洗的流程还在慢慢搭
中文翻译质量参差不齐,部分需要返工校对
标签体系还不够细,理想状态应该能按镜头类型、光照风格、运动方式等维度筛选,现在做不到
这些是接下来要一点点啃的骨头。列出来不丢人,藏着掖着才没意思。
但方向是清楚的。
目前这些数据只是一个起点。
短期来看,我想把模型覆盖范围再扩大一些,不止 Seedance 2,Midjourney、GPT Imgage-2 等模型的提示词也要做同样的结构化整理。自动化更新流程正在搭,目标是不用每次都靠人工去扒数据,让数据集持续生长。
中期的话,希望能有更多创作者加入进来,贡献自己打磨过的好提示词,让这个 Hub 不只是我一个人在往里塞东西。理想状态是,大家用着觉得好,顺手就把自己压箱底的提示词也扔进来,把数据池越做越大。
如果运气好,这件事能走得再远一点——做成一个真正的 Prompt 数据公共基础设施。不是谁的私产,不需要付费解锁,就是一个干干净净、持续更新、谁都能用的开源数据源。这想法挺大的,但值得往那个方向走。
怎么访问和获取
🌐 在线体验:https://prompthub.gokuscraper.com/
🤗 全量下载:https://huggingface.co/datasets/GokuScraper/seedance-2-prompts-datasets
⭐ GitHub 同步更新,欢迎 Star 和提 Issue
结尾
这个项目和网站花了不少时间,但远没到完美的程度。
如果你用了,有什么想法、吐槽、建议,都欢迎告诉我。做出来就是给人用的,你的反馈就是下一个版本改进的方向。

感谢各位朋友捧场!要是觉得内容有有点意思,别客气,点赞、在看、转发,直接安排上!
想以后第一时间看着咱的文章,别忘了点个星标⭐,别到时候找不着了。
行了,今儿就到这儿。

论成败,人生豪迈,我们下期再见!
公众号和交流群
欢迎进群交流。
